

La predicción de ventas o de la demanda puede permitir la optimización de varios procesos en una organización, entre ellos la gestión del aprovisionamiento, la planificación de la producción, el ajuste del inventario o la coordinación de la distribución.
Con el fin de aproximarnos a tal predicción, presentamos un caso práctico en el que pondremos en práctica algunas de las cuestiones citadas en el artículo Predicción de ventas usando Machine Learning.
El objetivo consistirá en implementar un modelo de Machine Learning (ML) que nos permita estimar el consumo de diferentes bebidas para los próximos 6 meses.
Para alcanzar nuestro objetivo pasaremos, de forma breve, por una serie de pasos que nos llevarán al resultado final. Estos son:
- Seleccionar la herramienta para implementar el modelo de ML
- Recopilar los datos que nos permitan entrenar nuestro modelo
- Realizar un análisis exploratorio (EDA) que nos permita conocer la información a tratar
- Realizar un preprocesamiento previo de los datos y extraer las características más relevantes (FE)
- Seleccionar la serie objetivo y las series de apoyo
- Seleccionar el modelo de ML o DeepLearning (DL)
- Dividir el conjunto de datos en subconjuntos de entrenamiento, validación y pruebas
- Crear, entrenar y validar el modelo
- Optimizar los hiperparámetros del modelo (HO)
- Realizar las inferencias
Herramienta de predicción
Comentamos en el artículo anterior que existían diversos frameworks y librerías de acceso libre para la implementación de modelos de Machine Learning, incluso citamos algunos orientados específicamente para modelos de predicción de series temporales.
pythorch-forecasting es uno de ellos y es el que utilizaremos en este caso para la predicción de ventas. Esta herramienta está construida sobre el framework de PyTorch, ambos implementados en Python, por lo que se requiere conocimientos en este lenguaje de programación para entender los fragmentos de código seleccionados que presentaremos a lo largo del artículo.
Pytorch y por ende pytorch-forecasting (https://pytorch-forecasting.readthedocs.io/) se apoyan, entre otras librerías, en dos de uso muy extendido en el ámbito de la ciencia de datos, estas son, NumPy y pandas. La primera de ellas, NumPy , es una librería especializada en la computación científica y en ML es muy utilizada para operaciones de álgebra lineal sobre matrices multidimensionales, base de numerosos algoritmos de ML. La segunda, pandas, es una herramienta de análisis y transformación de datos y nos facilita el trabajo con diversas estructuras de datos como iremos viendo.
Conjunto de datos
Es posible obtener conjuntos de datos públicos de múltiples fuentes. Una muy utilizada en el ámbito del Machine Learning es Kaggle. Allí podemos encontrar diversos conjuntos para la predicción de ventas o de la demanda.
Uno muy utilizado para valorar diferentes modelos de predicción es Volume Forecasting, que incluye datos sobre el consumo de cerveza a nivel de producto y agencia (mayorista).
Por simplicidad utilizaremos este conjunto de datos, aprovechando que pytorch_forecasting lo incluye como datos de ejemplos y nos ahorra parte del trabajo.
# Cargamos los datos
from pytorch_forecasting.data.examples import get_stallion_data
data0 = get_stallion_data()
Un primer paso antes de implementar un modelo concreto consiste en analizar los datos que tenemos disponibles para realizar nuestra predicción. Para ello utilizaremos diversas funciones de Python y otras librerías adicionales.
type(data0)
pandas.core.frame.DataFrame
data0.shape
(21000, 26)
Como podemos observar los datos están almacenados en una estructura muy utilizada, Dataframe, de la librería pandas que podríamos asimilar, por conveniencia, a una matriz de 26 columnas y 21000 filas. Con los siguientes comandos podemos consultar el nombre de las columnas para determinar qué datos están presentes en el conjunto y ver una muestra de ellos.
data0.columns
Index([‘agency’, ‘sku’, ‘volume’, ‘date’, ‘industry_volume’, ‘soda_volume’,
‘avg_max_temp’, ‘price_regular’, ‘price_actual’, ‘discount’,
‘avg_population_2017’, ‘avg_yearly_household_income_2017’, ‘easter_day’,
‘good_friday’, ‘new_year’, ‘christmas’, ‘labor_day’, ‘independence_day’,
‘revolution_day_memorial’, ‘regional_games’, ‘fifa_u_17_world_cup’,
‘football_gold_cup’, ‘beer_capital’, ‘music_fest’,
‘discount_in_percent’, ‘timeseries’],
dtype=’object’)
data0.head()

Análisis del escenario
La empresa del ejemplo vende su variedad de cervezas a través de diferentes mayoristas ubicados a lo largo de la geografía mundial.
El objetivo de la predicción que se plantea es estimar la demanda a futuro que permita a la empresa planificar su producción y distribución. Podríamos plantear el reto intentando contestar a la siguiente pregunta: ¿Qué productos y en qué cantidad demandará a futuro cada mayorista o agencia?
Para poder inferir una respuesta, los modelos de predicción principalmente hacen uso de los datos históricos para estimar los valores futuros de una serie temporal. Ese histórico es exactamente lo que nos encontramos en el conjunto de datos del ejemplo.
De la lista anterior, los datos principales relacionados con la predicción son, agency, sku, volume y date que representan el volumen de ventas realizadas en una fecha determinada por agencia y producto. El resto de datos como el volumen de ventas de la industria cervecera (industry_volume), el volumen de ventas de refrescos (soda_volume) o la temperatura (avg_max_temp) por ejemplo, son complementarios y nos podrían facilitar las tareas de predicción.
Análisis exploratorio (EDA) y selección de características (FE)
La calidad de los datos que proporcionamos a nuestro modelo de aprendizaje tiene un efecto muy relevante sobre la precisión de la predicción que éste realice.
El análisis exploratorio de los datos permite identificar tendencias, estacionalidad de los datos, correlaciones entre datos mediante análisis bidimensional o multidimensional, patrones de interés, valores atípicos, identificar datos omitidos, duplicados o variables sesgadas, incluso establecer hipótesis sobre la evolución de los mismos.
Una vez hemos analizado los datos debemos determinar aquellas variables o atributos que mejor pueden caracterizar la serie temporal y que estimemos mejor pueden predecir nuestro valor objetivo. A este conjunto lo denominamos «características» o «features» del inglés y al proceso de preparación y selección de características nos referimos como Feature Engineering (FE). Para ello podemos apoyarnos en los resultados del análisis exploratorio y realizar una etapa de preprocesamiento de los datos originales, por ejemplo, eliminando los valores atípicos y duplicados, proyectando datos omitidos, normalizando las escalas de las diferentes variables, descartando valores o categorías poco frecuentes, traduciendo variables categóricas a numéricas, etc.
Procesamiento y extracción de características
Cuando el número de características es significativo suelen aplicarse técnicas estadísticas para la reducción de las mismas, por ejemplo mediante un análisis de componentes principales (PCA). Y al contrario o complementariamente, para la selección de las características también se puede hacer uso de librerías específicas que permiten generar nuevas características a partir de los datos de origen, utilizando determinados estadísticos o algoritmos más elaborados. Un ejemplo de librería de este tipo es tsfresh. En nuestro caso, otras características que podríamos haber creado manualmente podrían haber sido la media de consumo por producto o por agencia, por ejemplo. También es habitual crear nuevas variables a partir del dato temporal, por ejemplo, extraer el mes o la semana.
Para realizar llevar a cabo los procesos anteriores contamos con múltiples funciones de la librería pandas. También es habitual el uso de la librería sklearn que incluye funcionalidades para el procesamiento y extracción de características.
Dada la extensión que puede abarcar el análisis exploratorio y la extracción de características dedicaremos un artículo específico para exponer con mayor nivel de detalle estos procesos. Citaremos también la identificación y procesamiento de ciertas características de las series temporales como la estacionariedad, la tendencia o la estacionalidad, por ejemplo. Usaremos además una librería específica, pandas_profiling , que nos permita simplificar parte del proceso de análisis exploratorio.
Caracterización de los datos de ventas
Para el presente caso usaremos, a título ilustrativo, algunas funciones de pandas.
Previamente seleccionaremos un subconjunto de variables, 7 de las 23, para simplificar el ejemplo. Concretamente son las mencionadas con anterioridad. De estas 7 variables tendríamos 1 de tipo fecha date, 2 categoriales sku y agency y las 4 restantes numéricas.
Con la siguiente función podemos hacernos una idea de la tendencia central, la dispersión y la forma de la distribución del conjunto de datos.
data0 = data0.filter([‘agency’, ‘sku’, ‘volume’, ‘date’, ‘industry_volume’, ‘soda_volume’, ‘avg_max_temp’])
data0.describe()

En la tabla anterior observamos por ejemplo que el volumen máximo registrado es de 22.526, cuando la media es de tan solo 1.492 con una desviación típica de 2.711. Además el cuartil 3 (Q3) indica que el 75% de los valores caen por debajo de 1.774. Esto hace pensar que deben haber valores atípicos en la variable volumen. Veamos la distribución del volumen de forma gráfica.
data0[‘volume’].plot.hist(bins=12, figsize=(16,6))

Casi 16.000 registros de un total de 21.000 tendrían un valor inferior a los 1.774, que es aproximadamente el 75% del total. Consideraremos valor atípico, aquellos que superen en 1,5 veces el IQR (rango intercuartil = Q3 – Q1). Veamos esto de forma más sencilla utilizando un gráfico de cajas.
plt.boxplot(data0[‘volume’])
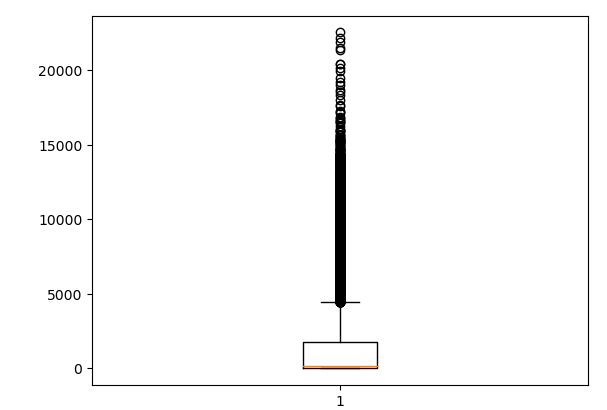
En este gráfico la línea inferior del cuadrado indica el Q1, la superior el Q3 y la línea amarilla la mediana (Q2 – 50%). Observamos como la mediana está bastante cerca de Q1 como se indica en la tabla anterior. Por otro lado, parece que hay un buen porcentaje de valores atípicos. Veamos cuántos.
print(‘Valores volumen > 5000: %d’ % data0[data0[‘volume’] > 5000].count()[‘volume’])
Valores volumen > 5000: 1961
Valores atípicos
Valore atípicos
Aunque en número pueda parecer una cantidad significativa, en realidad no llegan al 1% de la muestra. Los valores atípicos pueden producirse por ejemplo por errores de lectura en sensores, en la transcripción de datos, por eventos puntuales, etc., lo que podría influir negativamente en la predicción. Pero los valores atípicos a veces recogen información muy relevante. En este caso podría tratarse de eventos específicos como conciertos, eventos deportivos o culturales que podrían aumentar significativamente el consumo de cerveza.
Por lo tanto, habría que seguir analizando los datos para determinar si deberíamos descartarlos o tenerlos en cuenta como predictores de eventos recurrentes. Existen en la actualidad multitud de técnicas para determinar los valores atípicos con mayor precisión, así como su implementación en diferentes librerías. En Python podemos citar PyOD y que trataremos en un futuro artículo.
Por simplicidad para no extendernos, procederemos a acotar los valores atípicos inferidos a partir del IQR, estableciéndoles el mayor valor considerado dentro de lo normal, concretamente 5.000. Otra opción podría haber sido asignarles un valor por interpolación de los valores adyacentes o incluso eliminar las filas con dichos valores.
Características adicionales
Añadiremos una columna adicional, el «mes» month, que construiremos a partir de la fecha date. Construir características a partir de las referencias temporales, es habitual en el procesamiento de series temporales como el que nos ocupa. En los resultados finales podremos observar su influencia.
data1 = data0.copy()
data1.loc[(data1[‘volume’] > 5000), ‘volume’] = 5000
data1[«month»] = data1.date.dt.month.astype(str).astype(«category»)
data1.head(1)

Datos duplicados y ausentes
Verificaremos ahora que no haya valores duplicados o ausentes
print(‘Duplicados: %d’ % (data1.duplicated()[1] == True))
print(‘Ausentes %d’ % data1.isnull().sum().sum())
Duplicados: 0
Ausentes 0
Distribución de los datos de ventas
La predicción de ventas, como hemos indicado, se desea realizar a nivel de Agencia y Producto. Veamos cuántas combinaciones tenemos en nuestro conjunto de datos.
print(«Valores distintos:»)
print(«Agencias: %d » % data1[‘agency’].nunique())
print(«Productos: %d » % data1[‘sku’].nunique())
print(«Combinaciones con datos %d» % len(data1[[‘agency’, ‘sku’]].drop_duplicates()))
Valores distintos:
Agencias: 58
Productos: 25
Combinaciones con datos 350
De las 1.450 (58 * 25) combinaciones posibles hay datos para un total de 350. Esto sugiere que no todas las agencias comercializan todos los productos. Para hacernos una idea de los valores que pretendemos predecir tomemos al azar una de las combinaciones de Agencia / Producto para ver la evolución del volumen a lo largo del tiempo. Por ejemplo Agency_32 y SKU_04, que representa un volumen de venta medio aproximadamente de 2800. Veamos cuántos valores incluye el conjunto de datos y cómo se representa gráficamente el volumen frente al tiempo.
data2 = data1[(data1[‘agency’]==‘Agency_32’) & (data1[‘sku’] == ‘SKU_04’)]
print(‘Volumen medio: %d’ % data2[‘volume’].mean())
print(‘Registros: %d ‘ % data2[‘volume’].count())
Volumen medio: 2831
Registros: 60
Existen 60 registros, correspondientes a uno por mes durante los 5 años de la serie temporal (5*12).
Representemos gráficamente los volúmenes de venta y la temperatura media.
data2.plot(x=‘date’, y=[‘volume’,’industry_volume’,’soda_volume’,’avg_max_temp’], kind=‘line’, subplots=True, figsize=(16, 12))
En el conjunto de datos, mientras que el volumen varía dependiendo de la combinación Agencia / Producto, el volumen de la industria, el volumen de refrescos y la temperatura media máxima no lo hacen. Esto lo tendremos en cuenta a la hora de definir nuestro modelo de predicción. Se puede observar gráficamente la estacionalidad de las temperaturas y se aprecia, a la vista, una ligera tendencia positiva en el volumen de la industria y de los refrescos. El volumen para el par seleccionado, no sigue aparentemente un patrón muy definido.
En la segunda parte de este artículo se completará la descripción de este caso práctico de predicción de ventas mediante ML.
Predicción de Ventas – Caso Práctico Pt. 2
Esta entrada también está disponible en:

