

Este artículo continúa la exposición del caso práctico introducido en Predicción de Ventas – Caso Práctico.
El modelo de predicción de ventas
Habiendo determinado la serie objetivo, realizado el análisis exploratorio, el preprocesamiento de los datos y la extracción de características es momento para seleccionar el modelo a utilizar para la predicción.
Dentro del ML, existen numerosos modelos para la predicción de series temporales. A aquellos que se basan en el uso de redes neuronales de múltiples capas los denominaremos modelos de Deep Learning (DL) que se traduce como aprendizaje profundo. pytorch-forecasting es una herramienta para construir modelos de DL.
Para el caso práctico utilizaremos el modelo Temporal Fusion Transformer (TFT) que citamos en el artículo anterior.
Recordemos que TFT es un modelo basado en Transformer que aprovecha la auto-atención para capturar la compleja dinámica temporal de múltiples secuencias de tiempo. Como también comentamos, TFT proporciona una arquitectura de red neuronal que integra mecanismos de otras arquitecturas, como las capas LSTM y los mecanismos atencionales de los Transformers.
En la siguiente figura tomada del artículo original (https://arxiv.org/pdf/1912.09363.pdf) se muestran un diagrama de sus componentes.
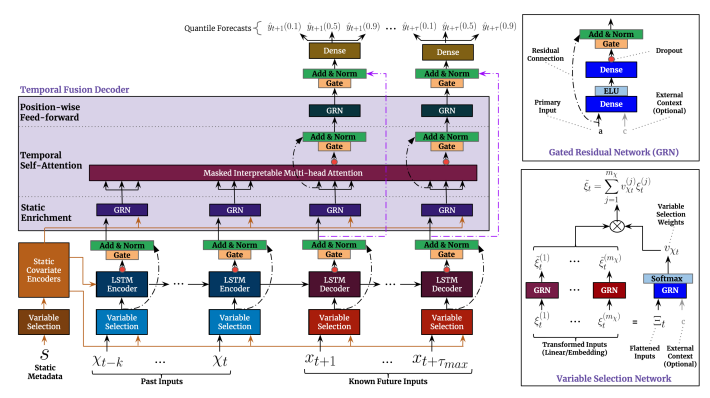
Una de las facilidades que ofrece TFT es que permite ser entrenado con múltiples series, univariadas o multivariadas. Además admite características que varíen o no en el tiempo, conocidas a futuro (ej. días festivos) o no, de tipo numérico (ej. volumen) o categorial (producto).
Para entrenar el modelo TFT con la librería pytorch-forecasting, debemos tomar nuestros datos que actualmente los tenemos almacenados en un objeto Dataframe y encapsularlos en un objeto de la clase TimeSeriesDataset.
Antes de crear el TimeSeriesDataset, debemos decidir el tamaño de la ventana de tiempo que utilizaremos en cada iteración del aprendizaje, así como el tamaño de la predicción, en este caso, cuántos meses hacia adelante vamos a predecir. Además debemos crear un índice de tiempo de tipo numérico que indique el orden en el que se han de procesar los registros.
Código
# Establecemos el índice de tiempo
data = data1.copy()
data[«time_idx»] = data[«date»].dt.year * 12 + data[«date»].dt.month
data[«time_idx»] -= data[«time_idx»].min()
# Establecemos el tamaño de la predicción y la ventana de entrenamiento
max_prediction_length = 8 # Predicción de 8 meses hacia adelante
max_encoder_length = 24 # Ventana de 24 meses
training_cutoff = data[«time_idx»].max() – max_prediction_length
Creamos el TimeSeriesDataSet estableciendo como objetivo la variable volume, como variables categoriales estáticas agency y sku, como atributos que varían con el tiempo y son conocidos month y date y como variables no conocidas en el tiempo volume, _industry_volume, _soda_volume y avg_max_temp. Excluiremos de los datos de entrenamiento tantos meses como hayamos decidido predecir, con el fin de usarlos para la validación del modelo.
training = TimeSeriesDataSet(
data[lambda x: x.time_idx <= training_cutoff],
time_idx=«time_idx»,
target=«volume»,
group_ids=[«agency», «sku»],
max_encoder_length=max_encoder_length,
max_prediction_length=max_prediction_length,
static_categoricals=[«agency», «sku»],
static_reals=[],
time_varying_known_categoricals=[«month»],
time_varying_known_reals=[«date»],
time_varying_unknown_categoricals=[],
time_varying_unknown_reals=[
«volume»,
«industry_volume»,
«soda_volume»,
«avg_max_temp»,
],
target_normalizer=GroupNormalizer(
groups=[«agency», «sku»], transformation=«softplus»
),
add_relative_time_idx=True,
add_target_scales=True,
add_encoder_length=True,
allow_missing_timesteps=True,
)
Creación de los subconjuntos de datos
Ahora, a partir del TimeSeriesDataSet de entrenamiento, creamos el subconjunto de datos de validación. Por otro lado, es conveniente que en el entrenamiento y en la validación del modelo procesemos los datos en ventanas de un tamaño determinado (batch_size). pytorch_forecasting facilita para ello una clase DataLoader que puede obtenerse a partir de los TimeSeriesDataSet de entrenamiento y validación.
validation = TimeSeriesDataSet.from_dataset(training, data, predict=True, stop_randomization=True)
batch_size = 64
train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0)
val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size * 10, num_workers=0)
Por otro lado, antes de entrenar nuestro modelo, estableceremos un modelo base que nos permita luego determinar la mejoría conseguida en cuanto al valor de la predicción, en función del error absoluto medio (MAE). Para ello utilizaremos como valor de la predicción el último valor de la serie, apoyándonos en la clase Baseline de pytorch-forecasting.
actuals = torch.cat([y for x, (y, weight) in iter(val_dataloader)])
baseline_predictions = Baseline().predict(val_dataloader)
(actuals – baseline_predictions).abs().mean()
tensor(317.6110)
Creación, entrenamiento y validación del modelo
Para definir un modelo, en pytorch-forecasting debemos definir primero un entrenador (Trainer), que permite especificar varios parámetros de cómo se llevará a cabo el proceso de entrenamiento, por ejemplo, indicando qué elementos computacionales vamos utilizar (ej. cpu, gpu), el número máximo de etapas de entrenamiento, qué criterios utilizaremos para finalizar el proceso, qué queremos mostrar en el registro de eventos (log), etc.
Una vez definido el Trainer, lo utilizaremos en la definición de nuestro modelo.
early_stop_callback = EarlyStopping(monitor=«val_loss», min_delta=1e-4, patience=10, verbose=False, mode=«min»)
lr_logger = LearningRateMonitor()
logger = TensorBoardLogger(«lightning_logs»)
trainer = pl.Trainer(
max_epochs=100,
gpus=[0],
accelerator=«gpu»,
enable_model_summary=True,
gradient_clip_val=0.1,
limit_train_batches=30,
callbacks=[lr_logger, early_stop_callback],
logger=logger,
)
tft = TemporalFusionTransformer.from_dataset(
training,
learning_rate=0.03,
hidden_size=16,
attention_head_size=1,
dropout=0.1,
hidden_continuous_size=12,
output_size=7,
loss=QuantileLoss(),
log_interval=10,
reduce_on_plateau_patience=4,
)
print(f»Número de parámetros en la red: {tft.size()/1e3:.1f}k»)
Número de parámetros en la red: 26.3k
Hiperparámetros
Los modelos se caracterizan por tener hiperparámetros. Éstos son especificaciones internas que permiten personalizar el modelo. La precisión de la predicción depende con frecuencia de lo bien estimados que estén esos parámetros. Para ello se suele recurrir a un proceso de optimización de hiperparámetros. pytorch-forecasting dispone de funcionalidades para llevar a cabo esa optimización. Concretamente se basa en el uso de una librería especializada para este proceso denominada Optuna.
En cualquier caso este proceso queda fuera del alcance de este caso práctico, aunque podremos retomarlo en un futuro artículo. Ejemplos de hiperparámetros que podemos observar en la definición del modelo anterior son, el tamaño de la capa oculta hidden_size, el número de módulos atencionales attention_head_size, el porcentaje de neuronas que se eliminan para mejorar la generalización y evitar el sobreentrenameinto dropout o el ritmo de aprendizaje learning_rate.
Un aspecto a destacar, es que TFT admite la predicción probabilística, esto es, nos ofrece valores de predicción en términos de probabilidades, en lugar de predecir un valor único. Para ello establecemos en la función de error que va evaluando el aprendizaje una función acorde, en este caso, QuantileLoss.
Definido el modelo, procedemos a su entrenamiento.
Código
In [26]:
# Entrenar la red
trainer.fit(
tft,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader,
)
Epoch 36: 100%
31/31 [00:02<00:00, 13.08it/s, loss=100, v_num=91, train_loss_step=135.0, val_loss=145.0, train_loss_epoch=104.0]
Evaluaremos el rendimiento del modelo usando el subconjunto de validación, con cuyos datos NO ha sido entrenado el modelo. Para ello tomaremos el modelo de la iteración que menor error haya alcanzado.
# Seleccionamos el mejor modelo según el error de validación
best_model_path = trainer.checkpoint_callback.best_model_path
best_tft = TemporalFusionTransformer.load_from_checkpoint(best_model_path)
# Calculamos el MAE sobre el subconjunto de validación
actuals = torch.cat([y[0] for x, y in iter(val_dataloader)])
predictions = best_tft.predict(val_dataloader)
(actuals – predictions).abs().mean()
tensor(267.6982)
Observamos que el MAE es significativamente inferior al obtenido en el modelo base. Resaltar además que para el caso práctico hemos descartado una buena parte de las características y tanto el análisis exploratorio como el preprocesamiento de los datos ha sido muy simplista. Por otro lado, no hemos realizado ninguna optimización de los hiperparámetros. Todo esto apunta a que trabajando suficientemente estos aspectos con mucha probabilidad los resultados que se podrían obtener sean significativamente mejores.
Recordar igualmente que en nuestro caso práctico no se está realizando la predicción sobre una única serie, si no se está intentando predecir el volumen para cada uno de los pares Agencia / Producto y los resultados obtenidos proceden de la agregación de todos ellos.
Predicción
Revisemos gráficamente la predicción realizada sobre el par Agencia/Producto del ejemplo, así como el error que aporta al MAE conjunto.
In [41]:
raw_predictions, x = best_tft.predict(validation.filter(lambda x: (x.agency == «Agency_32») & (x.sku == «SKU_04»)), mode=«raw», return_x=True)
best_tft.plot_prediction(x, raw_predictions, idx=0, add_loss_to_title=True)

En la gráfica el valor observado, es decir el valor informado en el conjunto de datos, está representado en azul. La predicción al ser de tipo probabilístico, está conformada por la línea y las franjas de color naranja. La línea representa el cuantil 0,5 y refleja la media del MAE. Las franjas de mayor a menor intensidad representan la predicción con un nivel de confianza del 75%, 90% y 98% respectivamente.
Gráficamente la predicción parece seguir bastante bien los valores observados en varios de los 8 meses que se han tratado de predecir. En otros la diferencia es algo mayor. En cualquier caso, los valores observados quedan prácticamente dentro del intervalo de confianza del 75%. Podríamos concluir que al menos para este par seleccionado el objetivo de predicción se daría por conseguido. En todo caso se requeriría un análisis más profundo para evaluar el resto de series y determinar si los resultados son, al menos, igual de prometedores.
Interpretación del modelo
Una de las ventajas del modelo TFT es que permite interpretarse. Por ejemplo, podemos conocer qué variables de las seleccionadas (FE) han sido más determinantes. Veamos gráficamente la importancia de las variables de entrada, por no extendernos en exceso analizando el resto del modelo.
raw_predictions, x = best_tft.predict(val_dataloader, mode=«raw», return_x=True)
interpretation = best_tft.interpret_output(raw_predictions, reduction=«sum»)
best_tft.plot_interpretation(interpretation)
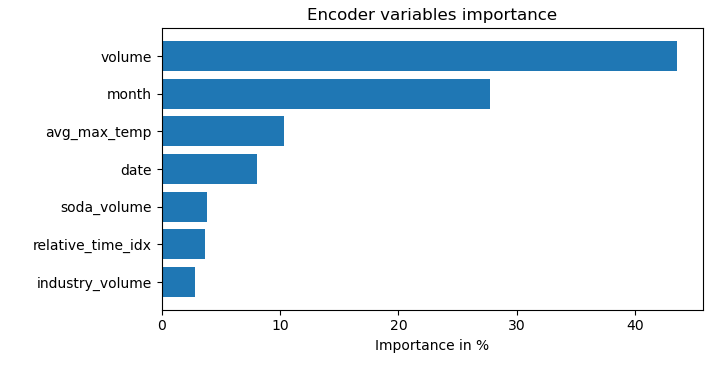
A la vista del diagrama, se observa que el volumen es la variable de entrada que más importancia tiene, que coincide precisamente con la variable que se pretende predecir. Tiene una importancia aproximada del 45%. La segunda en importancia es el mes con casi un 30%. Además, aparentemente, la temperatura resultar ser más relevante en este proceso que el volumen de venta de refrescos o de la industria en general.
Conclusiones
La predicción de una serie temporal requiere llevar a cabo varias fases entre las que destacan la preparación de los datos, la definición y entrenamiento de un modelo, determinar el rendimiento del mismo y en su caso proceder a una optimización de sus hiperparámetros.
Hemos utilizado el modelo Temporal Fusion Transformer -TFT- que según estudios recientes, es el que mejor rendimiento está ofreciendo en la predicción de series temporales. En cualquier caso es también práctica común usar múltiples modelos para determinar cuál de ellos se puede adaptar mejor al conjunto de datos y objetivos concretos. Otra práctica consiste en utilizar un conjunto de modelos simultáneamente, creando una medida agregada de los resultados obtenidos para cada uno de los mismos que pudiera ofrecer mejores resultados que cualquier modelo individualmente.
En el ejemplo se han entrenado un total de 350 series correspondientes a diferentes combinaciones de Agencia y Producto. Aunque hemos mostrado a título de ejemplo los datos relativos a una combinación arbitraria, se tendría que analizar el rendimiento del resto, así como los casos peores que nos den pistas de cómo se podría mejorar el modelo.
El preprocesamiento de los datos, la buena elección de las características y la optimización de los hiperparámetros influyen significativamente en la precisión de la predicción, de ahí la relevancia de las fases de EDA, FE y HO.
Si bien el modelo y las fases del ejemplo, por cuestiones de extensión, no están suficientemente desarrolladas, los resultados obtenidos podríamos considerarlos más que aceptables.
En próximos artículos desarrollaremos específicamente cada una de las fases principales en mayor nivel de detalle.
Esta entrada también está disponible en:


Hay una parte que no puedo replicar, a la hora de ajustar tft al modelo me arroja un error de que deberia ser un archivo lighning en vez de un tft, hay algunos pasos que no se bien como llegaste a ellos, por lo que utilice segun la busqueda en Google, como de donde obtener el Trainer, el tft y algunos otros, no se si pudieras poner alguna referencia al codigo completo o checar si aun funciona el mismo codigo, busco implementar este tipo de prediccion para el comportamiento de gases que es un poco mas inestable, podrias ayudarme, aun asi el articulo me parece muy interesante, espero puedas apoyarme.
El artículo trata de cubrir, de manera resumida, todo el procedimiento de predicción. No obstante, la implementación depende de muchos factores que se dan por conocidos, para no alargar en exceso el contenido. En todo caso, Ignos presta servicios para ayudar en la adopción de este tipo de técnicas, si tú o tu empresa necesitaran ayuda al respecto no dudes en ponerte en contacto usando el formulario de contacto o el correo info@ignos.com. Gracias por el interés.
Muy bueno el articulo, me ayudo a comprender bastante a como funciona este tipo de modelos. Estoy intentando implementar el modelo para predecir ventas futuras, pero estoy teniendo problemas a la hora de crear el TimeDataSerieSet. El error que me lo tira en el target_normalizer, me dice que tengo que hacer un fit. Busque en otros sitios de como solucionarlo y no encontre solucion